理解CUDA中的thread,block,grid和warp
之前写在知乎上的,现在放在自己的网站上。(https://zhuanlan.zhihu.com/p/123170285)
本篇文章是从网上一些文章中整理得到的,具体请查看参考文章。
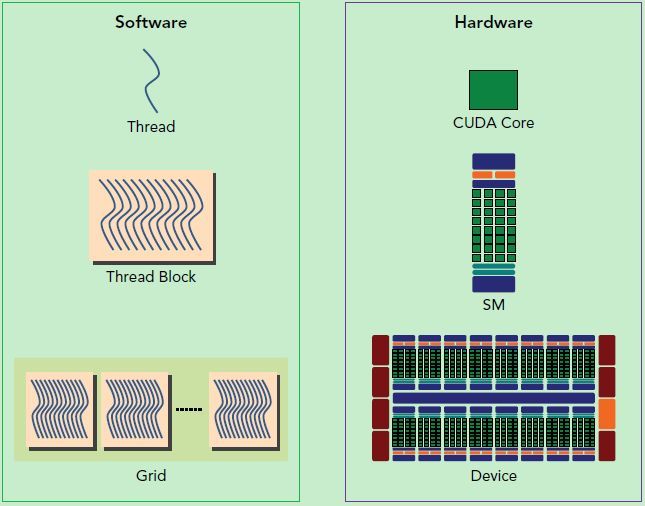
从硬件上看
- SP(Streaming Processor):流处理器, 是GPU最基本的处理单元,在fermi架构开始被叫做CUDA core。
- SM(Streaming MultiProcessor):一个SM由多个CUDA core组成,每个SM根据GPU架构不同有不同数量的CUDA core,Pascal架构中一个SM有128个CUDA core。
SM还包括特殊运算单元(SFU),共享内存(shared memory),寄存器文件(Register File)和调度器(Warp Scheduler)等。register和shared memory是稀缺资源,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力
从软件上看
- thread: 一个CUDA的并行程序会被以许多个thread来执行
- block: 数个thread会被群组成一个block,同一个block中的thread可以同步,也可以通过shared memory进行通信
- grid:多个block则会再构成grid

Warp
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread,这些thread以不同数据资源执行相同的指令。
当一个kernel被执行时,grid中的线程块被分配到SM上,一个线程块的thread只能在一个SM上调度,SM一般可以调度多个线程块,大量的thread可能被分到不同的SM上。每个thread拥有它自己的程序计数器和状态寄存器,并且用该线程自己的数据执行指令,这就是所谓的Single Instruction Multiple Thread(SIMT)。
一个CUDA core可以执行一个thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由warp scheduler负责调度。尽管warp中的线程从同一程序地址,但可能具有不同的行为,比如分支结构,因为GPU规定warp中所有线程在同一周期执行相同的指令,warp发散会导致性能下降。一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。
每个block的warp数量可以由下面的公式计算获得:
一个warp中的线程必然在同一个block中,如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些inactive的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是inactive状态,需要注意的是,即使这部分thread是inactive的,也会消耗SM资源。由于warp的大小一般为32,所以block所含的thread的大小一般要设置为32的倍数。
thread,block,grid
一个grid可以包含多个block,block的组织方式可以是一维的,二维或者三维的。block包含多个thread,这些thread的组织方式也可以是一维,二维或者三维的。CUDA中每一个线程都有一个唯一的标识ID即threadIdx,这个ID随着Grid和Block的划分方式的不同而变化,例如:
1 | // 一维的block,一维的thread int tid = threadIdx.x + blockIdx.x * blockDim.x; |
thread,block,gird在不同维度的大小根据算力不同是有限制的:
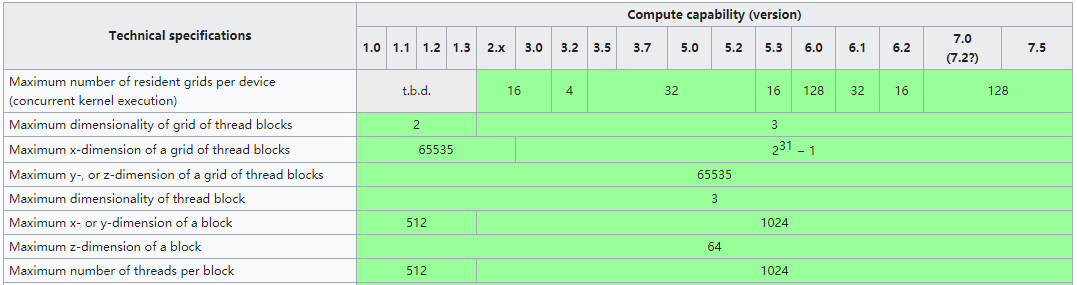
之前我遇到过CUDA8.0和CUDA10.0在gridDim.y最大size上的问题,可能是因为CUDA8.0仍支持2.x算力,gridDim.y最大size为65535,而之后的CUDA版本比如CUDA10.0已经不在支持,gridDim.y最大size为,所以在不同CUDA版本或在编译时没有指定架构的情况下,可能CUDA版本也会对thread,block,grid在不同维度的大小产生影响。
Reference
- https://en.wikipedia.org/wiki/CUDA
- https://zhuanlan.zhihu.com/p/34587739
- https://www.cnblogs.com/1024incn/p/4541313.html
- https://blog.csdn.net/junparadox/article/details/50540602
- https://blog.csdn.net/dcrmg/article/details/54867507?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task
- https://zhuanlan.zhihu.com/p/53763285
- https://docs.nvidia.com/cuda/cuda-c-programming-guide